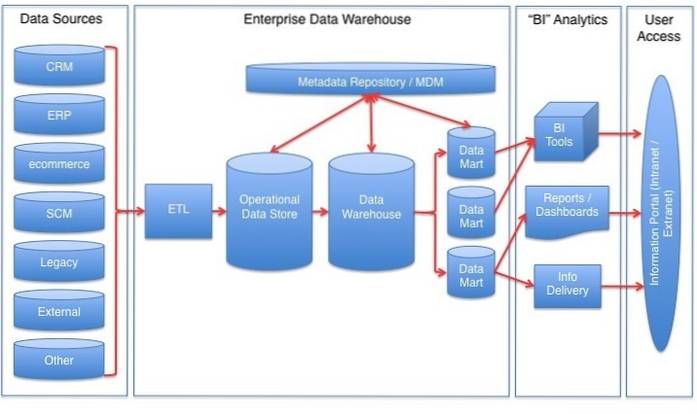
Nell'indice cluster, la chiave cluster definisce l'ordine dei dati all'interno della tabella. ... Un indice cluster è un tipo di indice in cui i record della tabella vengono riordinati fisicamente per corrispondere all'indice. Un indice non cluster è un tipo speciale di indice in cui l'ordine logico dell'indice non corrisponde all'ordine fisico memorizzato delle righe sul disco.
- Che cos'è l'indice cluster e non cluster in SQL?
- Quale è meglio un indice cluster o non cluster?
- Cos'è un indice di clustering?
- Qual è la differenza tra un indice di clustering e un indice secondario?
- L'indicizzazione è buona o cattiva?
- La chiave primaria è l'indice cluster?
- Le scansioni degli indici cluster sono errate?
- Gli indici cluster devono essere univoci?
- Ogni tabella dovrebbe avere un indice cluster?
- Perché gli indici vengono utilizzati in SQL?
- Possiamo creare un indice cluster senza chiave primaria?
- Cosa significa cluster?
Che cos'è l'indice cluster e non cluster in SQL?
Può esserci un solo indice cluster per tabella. Tuttavia, è possibile creare più indici non cluster su una singola tabella. Gli indici raggruppati ordinano solo le tabelle. Pertanto, non consumano spazio di archiviazione aggiuntivo. Gli indici non cluster vengono archiviati in una posizione separata dalla tabella effettiva che richiede più spazio di archiviazione.
Quale è meglio un indice cluster o non cluster?
L'indice cluster sarà più veloce. ... Tuttavia, l'indice non cluster contiene ANCHE un riferimento alla chiave cluster - questo è necessario nel caso in cui si aggiungano più colonne alla tabella, ma in realtà anche perché tutti gli indici (eccetto le viste indicizzate) sono puntatori alle pagine di dati.
Cos'è un indice di clustering?
Gli indici raggruppati ordinano e archiviano le righe di dati nella tabella o nella vista in base ai valori chiave. Queste sono le colonne incluse nella definizione dell'indice. Può esserci un solo indice cluster per tabella, poiché le righe di dati possono essere archiviate in un solo ordine.
Qual è la differenza tra un indice di clustering e un indice secondario?
Indice secondario - L'indice secondario può essere generato da un campo che è una chiave candidata e ha un valore univoco in ogni record o una non chiave con valori duplicati. Indice di clustering: l'indice di clustering è definito su un file di dati ordinato. Il file di dati è ordinato su un campo non chiave.
L'indicizzazione è buona o cattiva?
Svantaggi dell'utilizzo degli indici
Ma anche gli indici che forniscono prestazioni migliori per alcune operazioni possono aggiungere overhead per altre. Mentre l'esecuzione di un'istruzione SELECT è più veloce su una tabella cluster, INSERT, UPDATE e DELETE richiedono più tempo, poiché non solo i dati vengono aggiornati, ma anche gli indici vengono aggiornati.
La chiave primaria è l'indice cluster?
CHIAVE PRIMARIA e vincoli UNICI
Quando si crea un vincolo PRIMARY KEY, viene creato automaticamente un indice cluster univoco sulla colonna o sulle colonne se un indice cluster sulla tabella non esiste già e non si specifica un indice non cluster univoco. La colonna della chiave primaria non può consentire valori NULL.
Le scansioni degli indici cluster sono errate?
Scansione indice cluster
Buono o cattivo: se dovessi decidere se è un bene o un male, potrebbe essere un male. A meno che un numero elevato di righe, con molte colonne e righe, non venga recuperato da quella particolare tabella, una scansione dell'indice in cluster può ridurre le prestazioni.
Gli indici cluster devono essere univoci?
SQL Server non richiede che un indice cluster sia univoco, ma tuttavia deve disporre di alcuni mezzi per identificare in modo univoco ogni riga. Ecco perché, per gli indici cluster non univoci, SQL Server aggiunge a ogni istanza duplicata di un valore di chiave di clustering un valore intero a 4 byte denominato univocatore.
Ogni tabella dovrebbe avere un indice cluster?
Sì, ogni tabella dovrebbe avere un indice cluster. L'indice cluster imposta l'ordine fisico dei dati in una tabella. Puoi confrontarlo con l'ordine di musica in un negozio, per nome della band e / o Pagine gialle ordinate per cognome.
Perché gli indici vengono utilizzati in SQL?
Gli indici sono tabelle di ricerca speciali che il motore di ricerca del database può utilizzare per accelerare il recupero dei dati. In poche parole, un indice è un puntatore ai dati in una tabella. Un indice aiuta ad accelerare le query SELECT e le clausole WHERE, ma rallenta l'input dei dati, con le istruzioni UPDATE e INSERT. ...
Possiamo creare un indice cluster senza chiave primaria?
Posso creare un indice cluster senza chiave primaria? Sì, puoi creare. Il criterio principale è che i valori della colonna devono essere univoci e non nulli. L'indicizzazione migliora le prestazioni in caso di dati di grandi dimensioni e deve essere obbligatoria per un rapido recupero dei dati.
Cosa significa cluster?
sostantivo. un certo numero di cose dello stesso tipo, crescenti o tenute insieme; un grappolo: un grappolo d'uva. un gruppo di cose o persone vicine tra loro: c'era un gruppo di turisti al cancello.